|
|
|
|
|
Indepth Tour |
|
[Intro] |
 |
|||||||||||||||
|
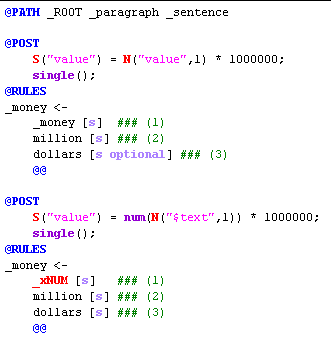
The heart of the text analyzer lies in the pass files, which contain NLP++ code and rules. Pass File Zones, Regions, and Selectors Pass file areas are marked by words that are blue, all-caps, and start with an "@". Three commonly used regions are detailed below.
Code Region An NLP++ pass file includes a CODE Region that is independent of any rule matching. One example of this is in the third pass "initKB", where the analyzer constructs needed concepts in the Knowledge Base before processing the text:
Next Section: |
|||||||||||||||